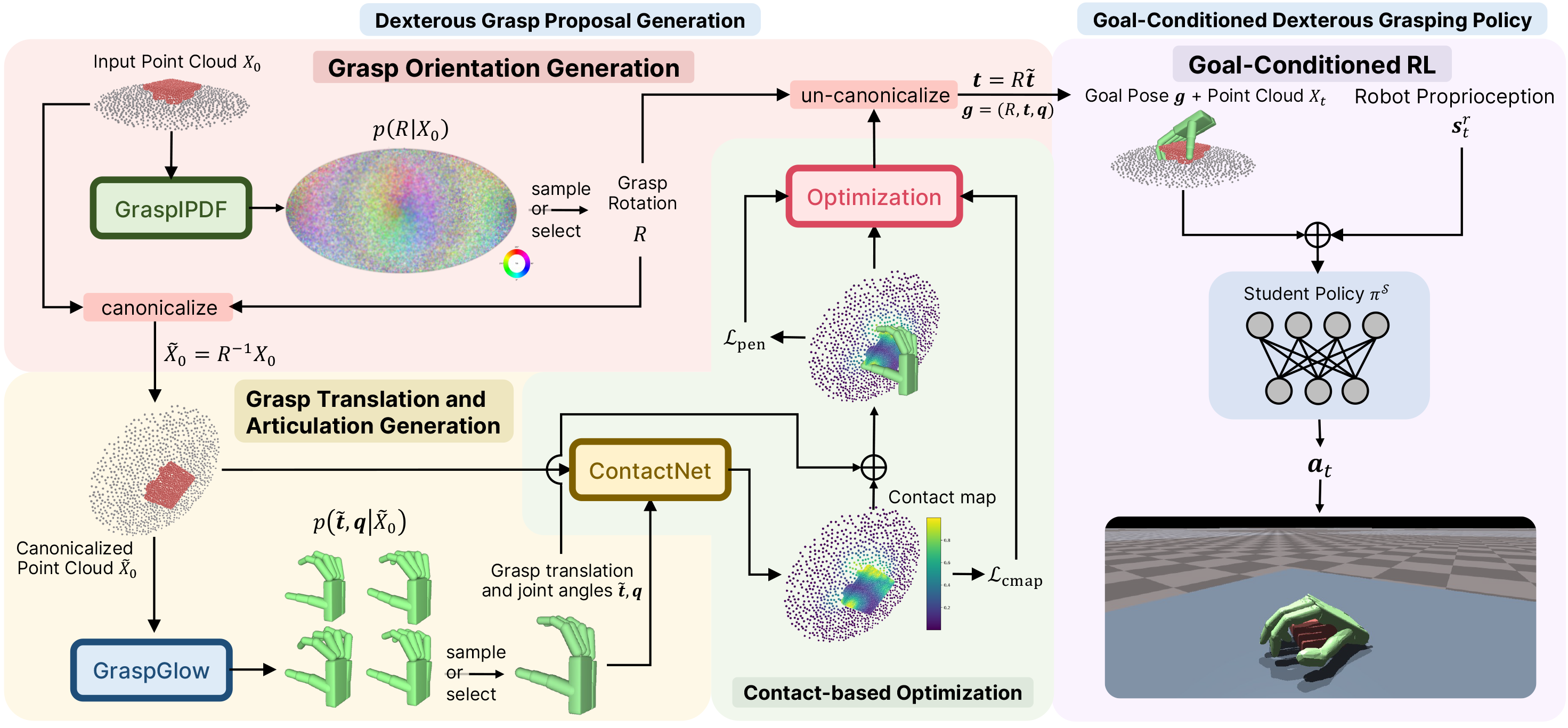
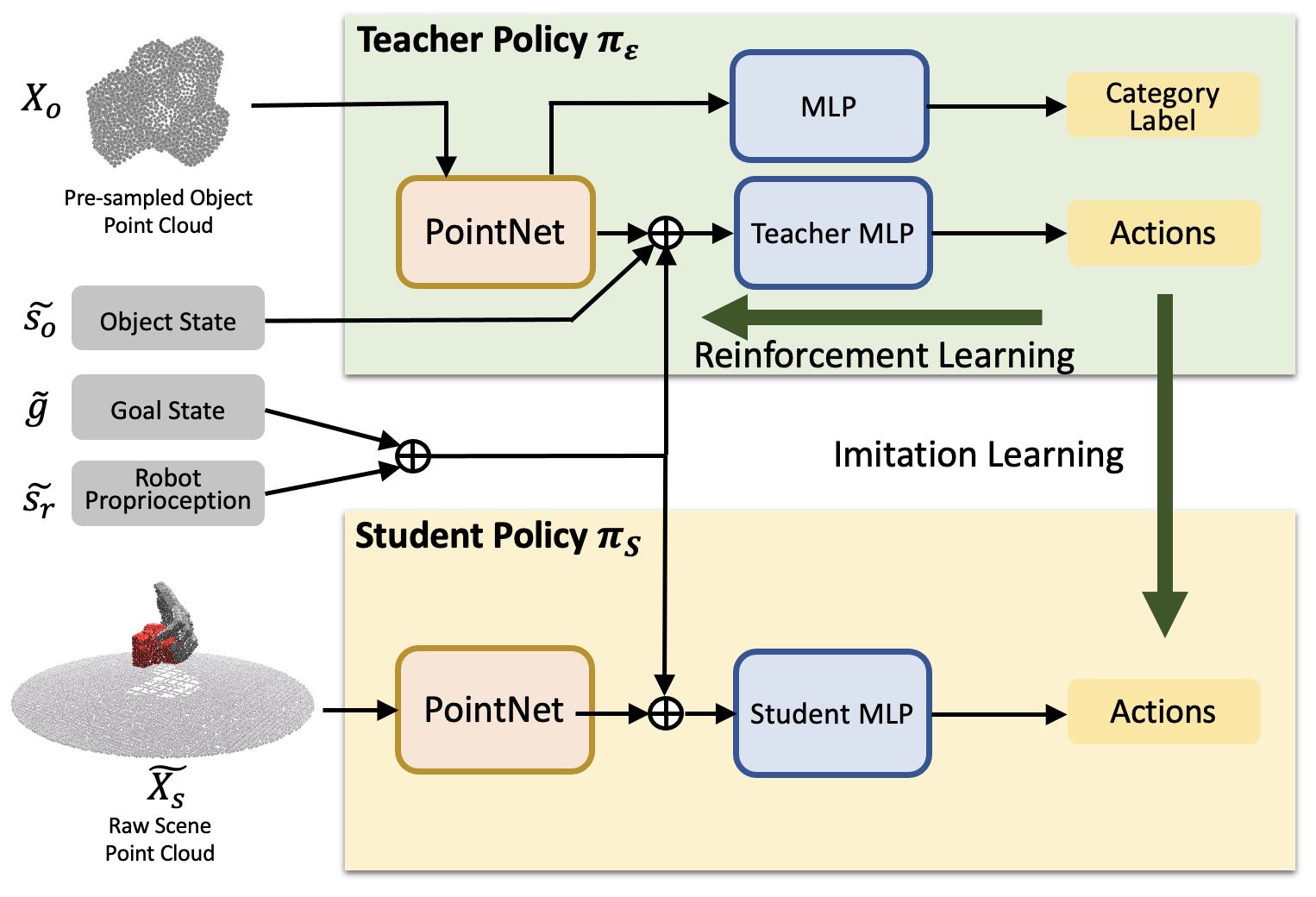
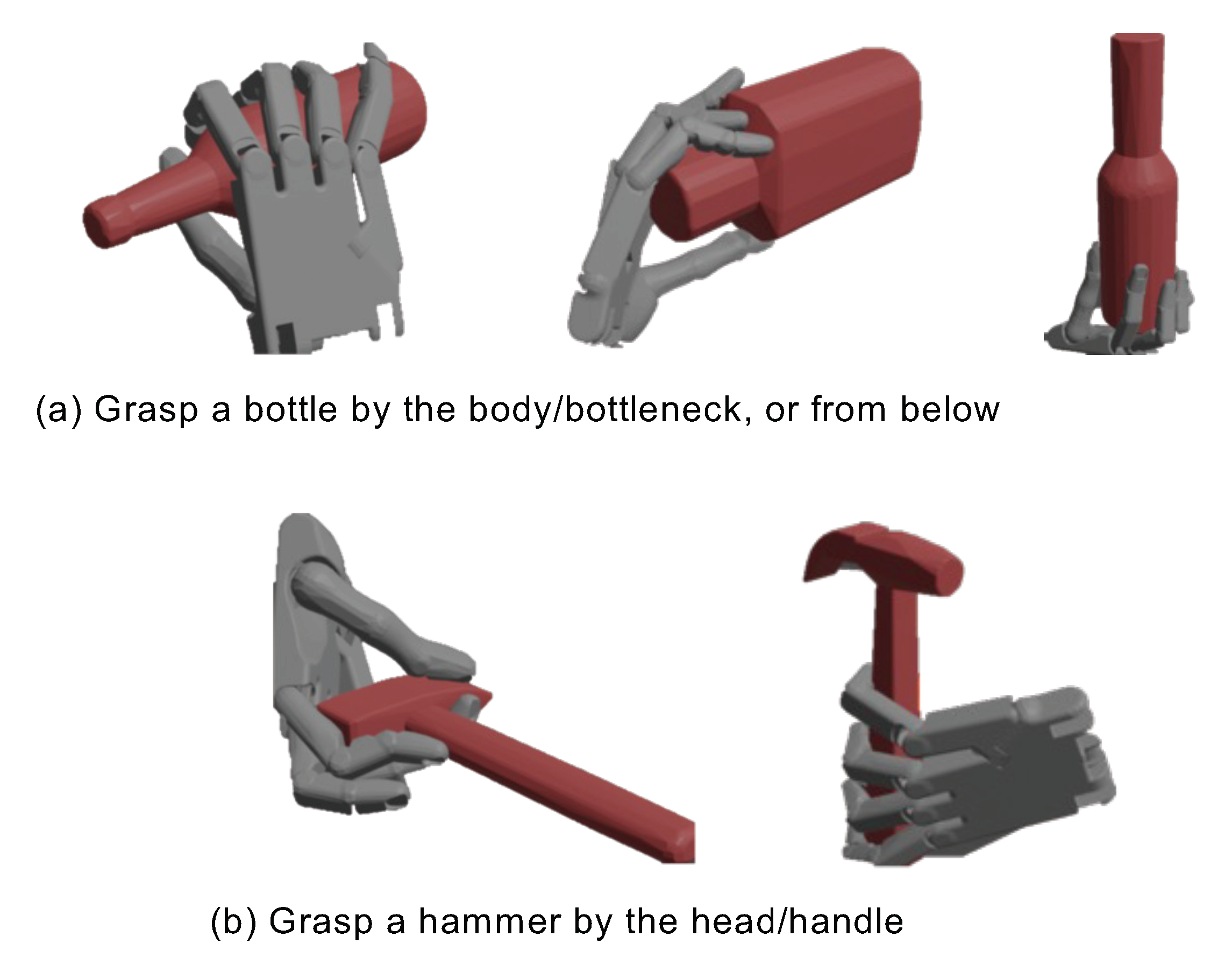
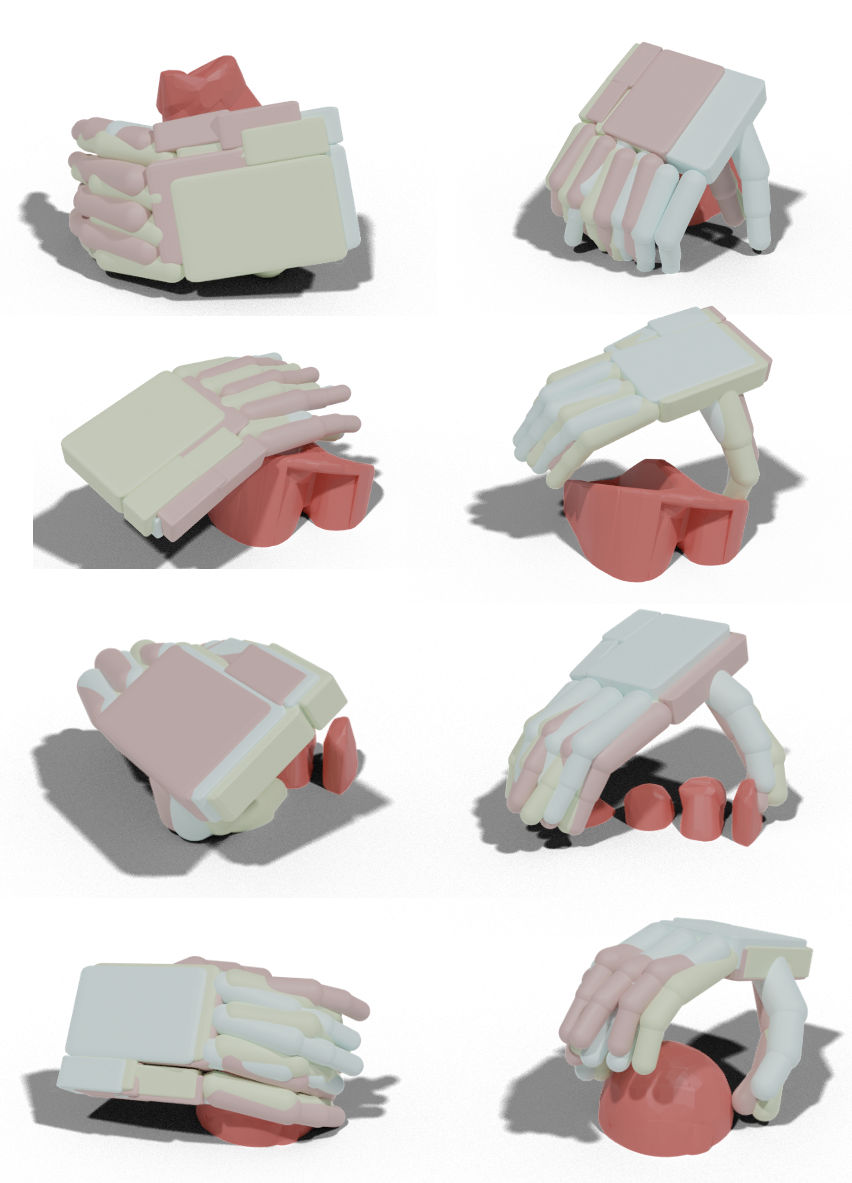
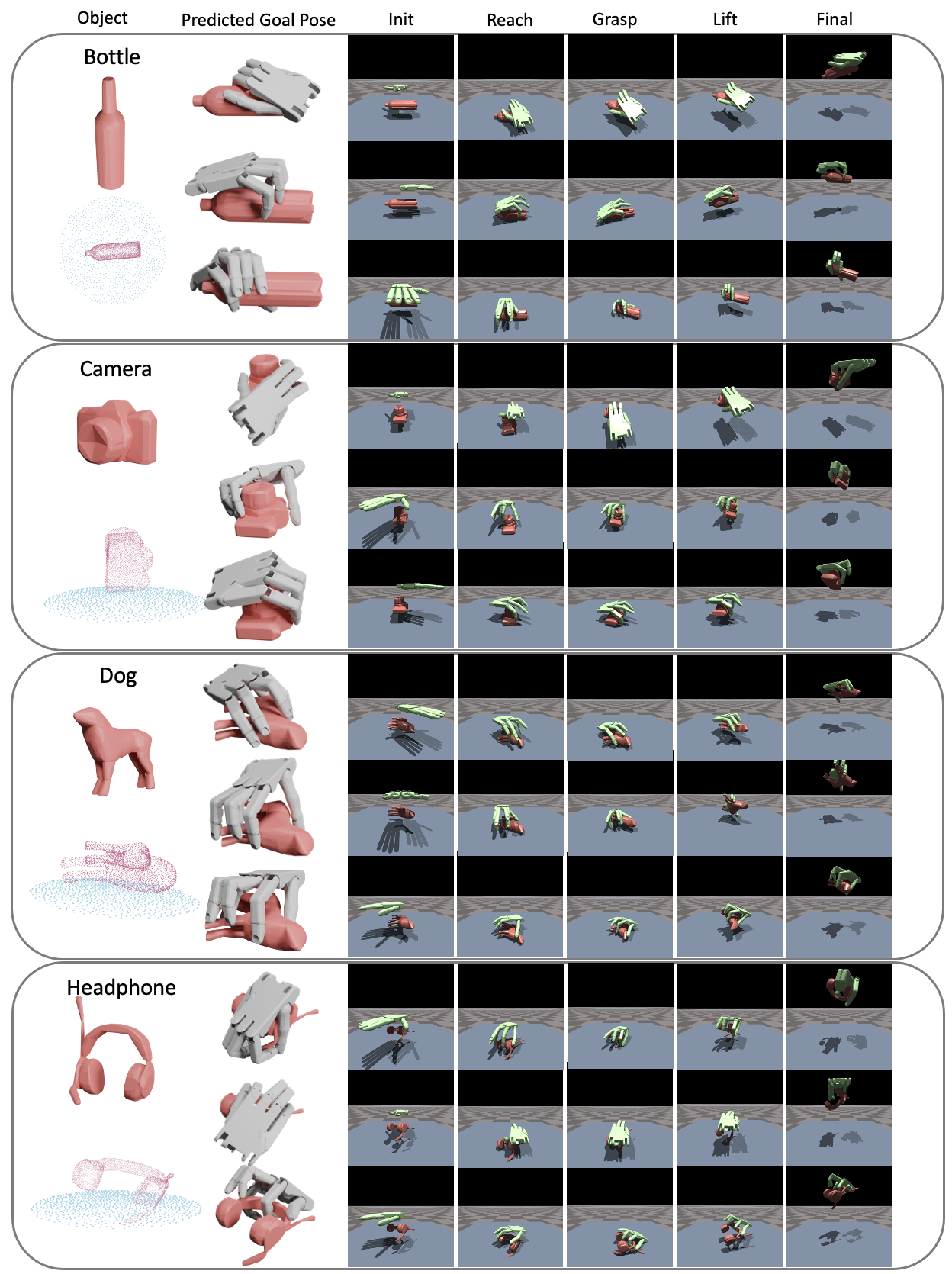
UniDexGrasp via grasp proposal generation and goal-conditioned execution. Left (grasp proposals): each figure shows for an object we generate diverse and high-quality grasp poses that vary greatly in rotation, translation and articulation states; right (grasp execution): Given two different grasp goal poses illustrated in the two bottom corners, we learn highly generalizable goal-conditioned grasping policy that can adaptively execute each corresponding goal pose, respectively shown in the green and blue trajectories.