Methods
Overview
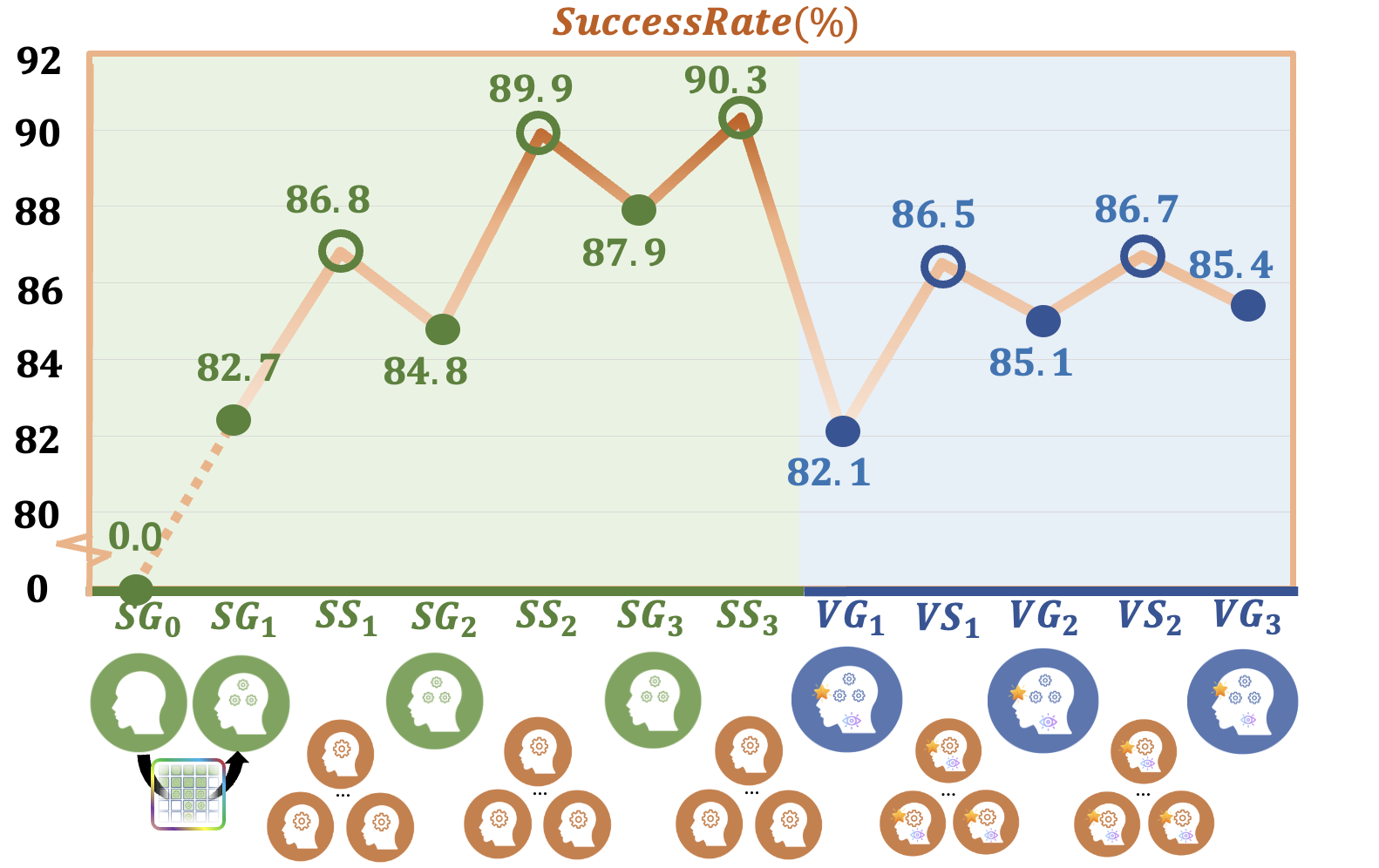
Overview. Our method, UniDexGrasp++ follows the convention of first learning
a state-based policy and then distilling it into a vision-based policy, and our
proposed method significantly boost both the state and vision learning stages.
GeoCurriculum
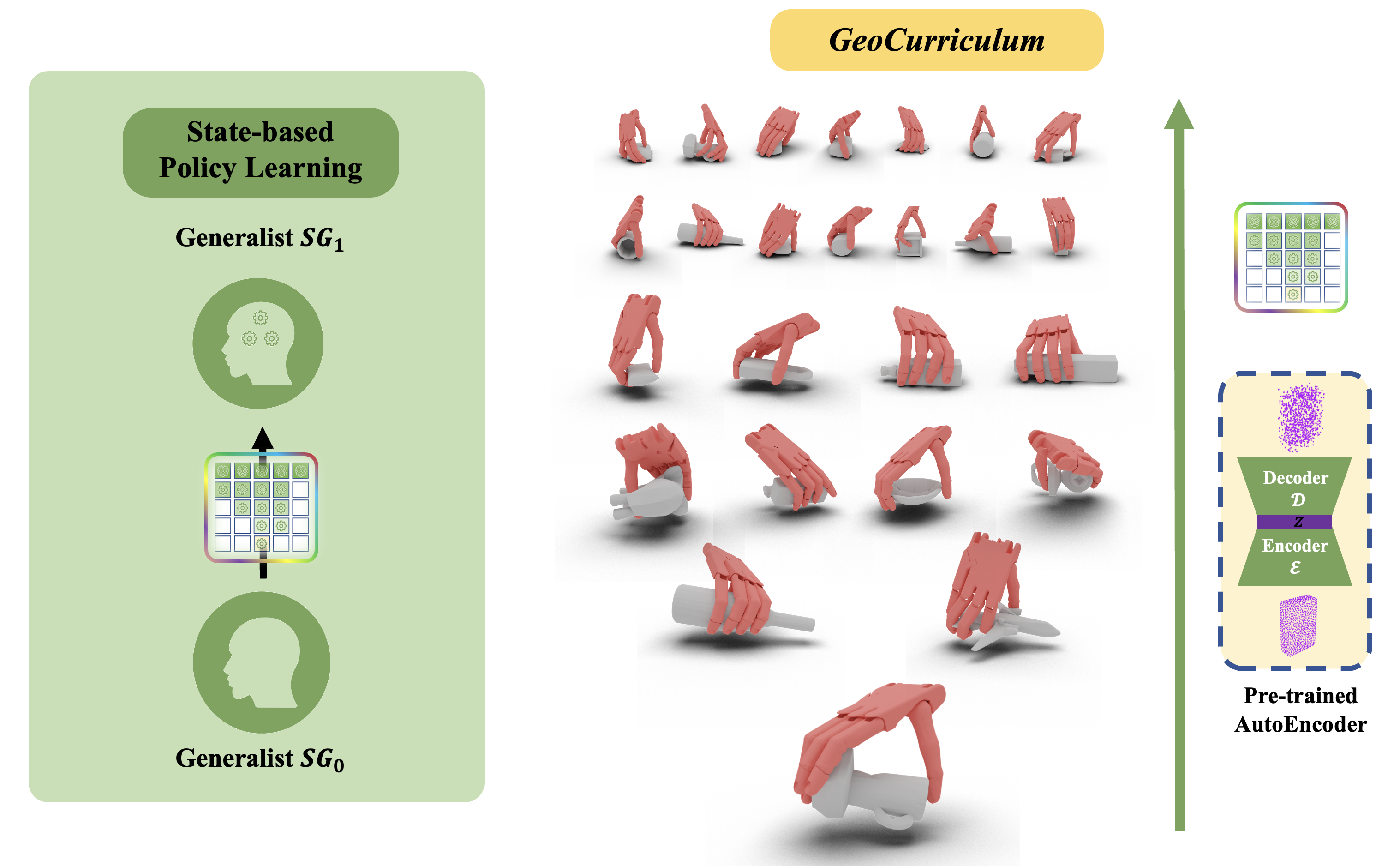
Geometry-aware Curriculum Learning. The idea is to gradually enlarge the
grasping task space from a single object with a fixed pose, to similar objects with
similar poses, finally to thousands objects with arbitrary poses.
To do so, we propose to pretrain a point cloud autoencoder and use its bottleneck
feature as the metric of the task space. We then can gradually enlarge the task
space from one point to the whole space.
GeoClustering
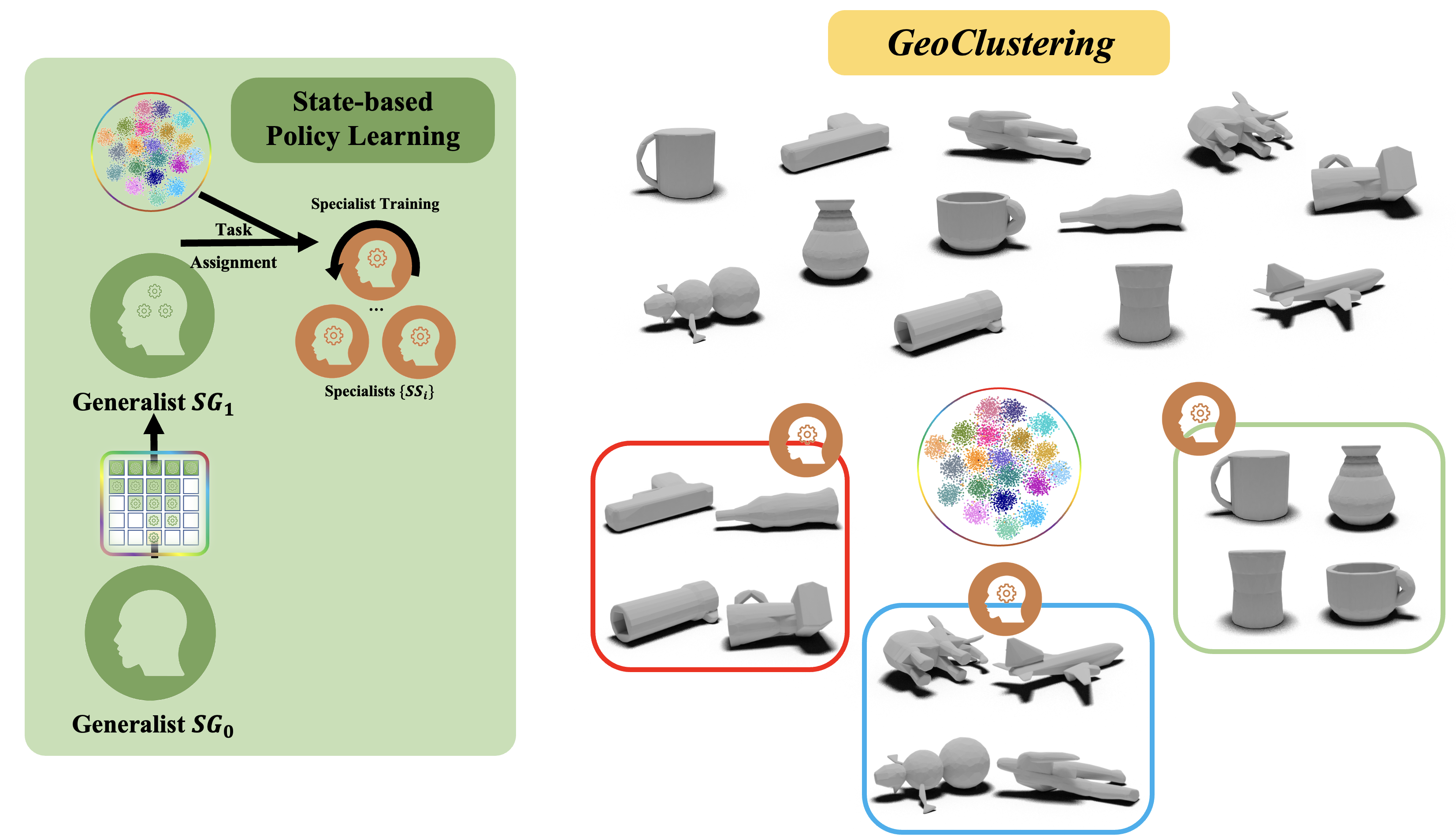
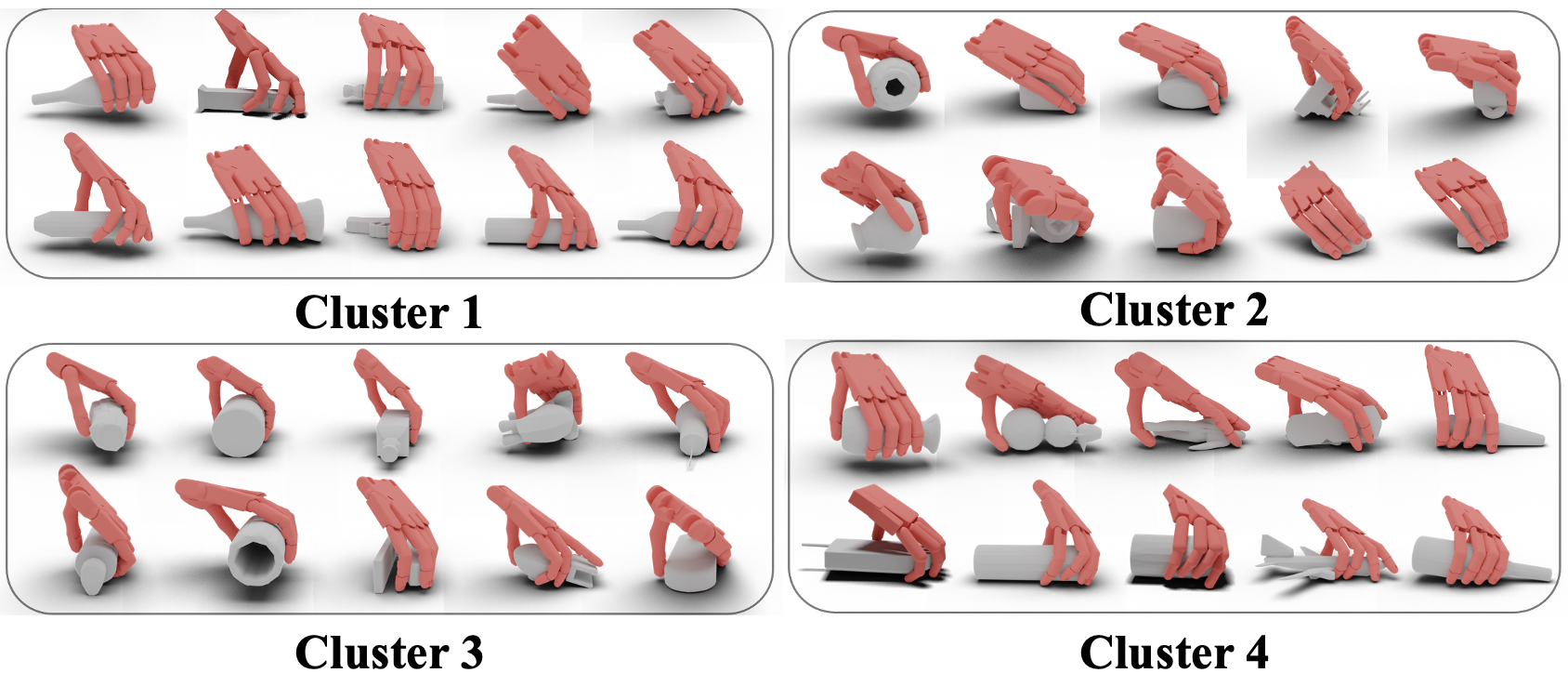
Geometry-aware Clustering. After this curriculum training, we obtain our
first generalist policy, SG1 and need to further improve it.
Inspired by divide-and-conquer, we use the task metric to partition the whole task
space into a lot of subspaces.
And then we can duplicate SG1 many times and finetune each of them in a smaller task
subspace to obtain many specialist SS_i.
SS_i will have a better performance than SG1 in its task subspace.
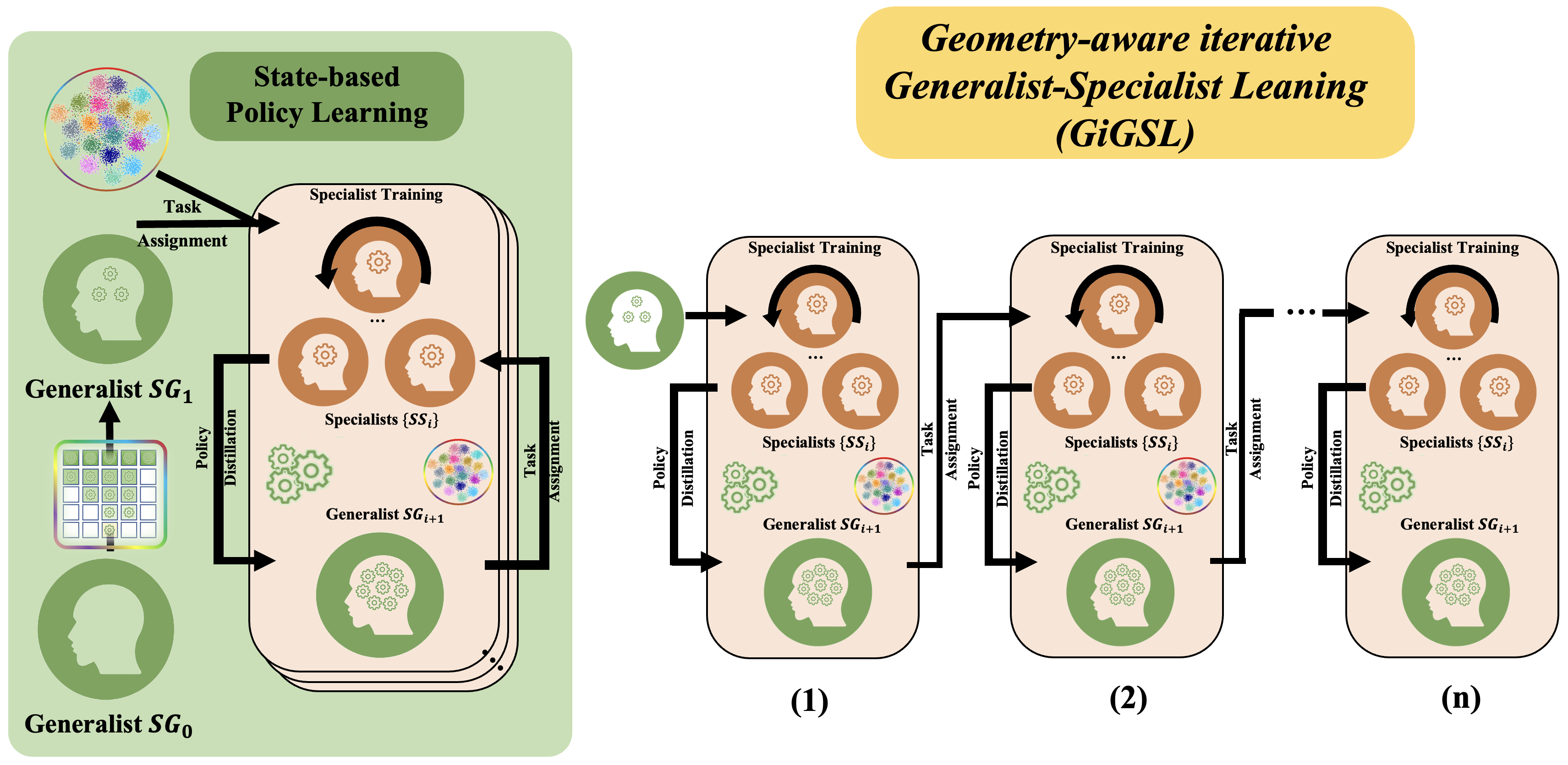
GiGSL
Geometry-aware iterative Generalist-Specialist Learning. All the specialists
SS_i now can distill back to a new generalist and gain a higher overall grasping
performance. We iteratively do generalist and specialist learning several times
until the policy is good enough.
Full pipeline
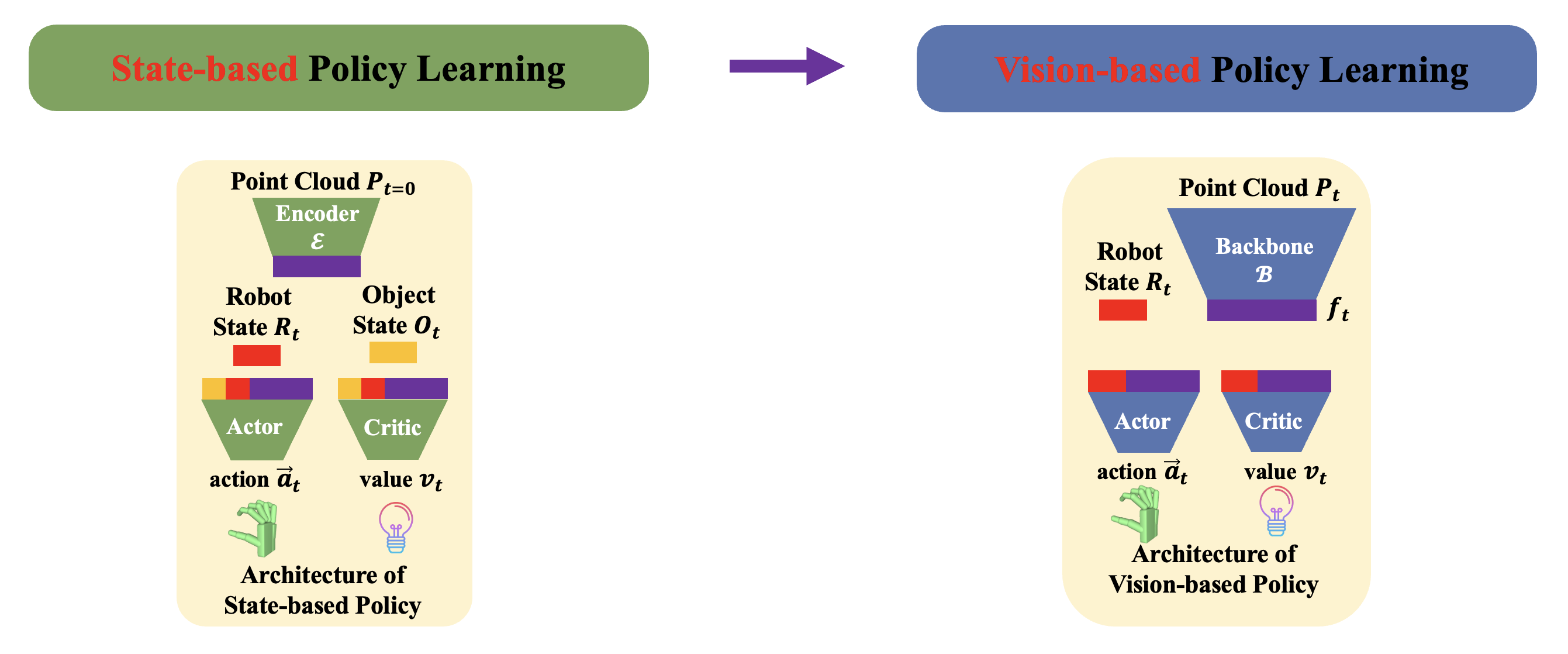
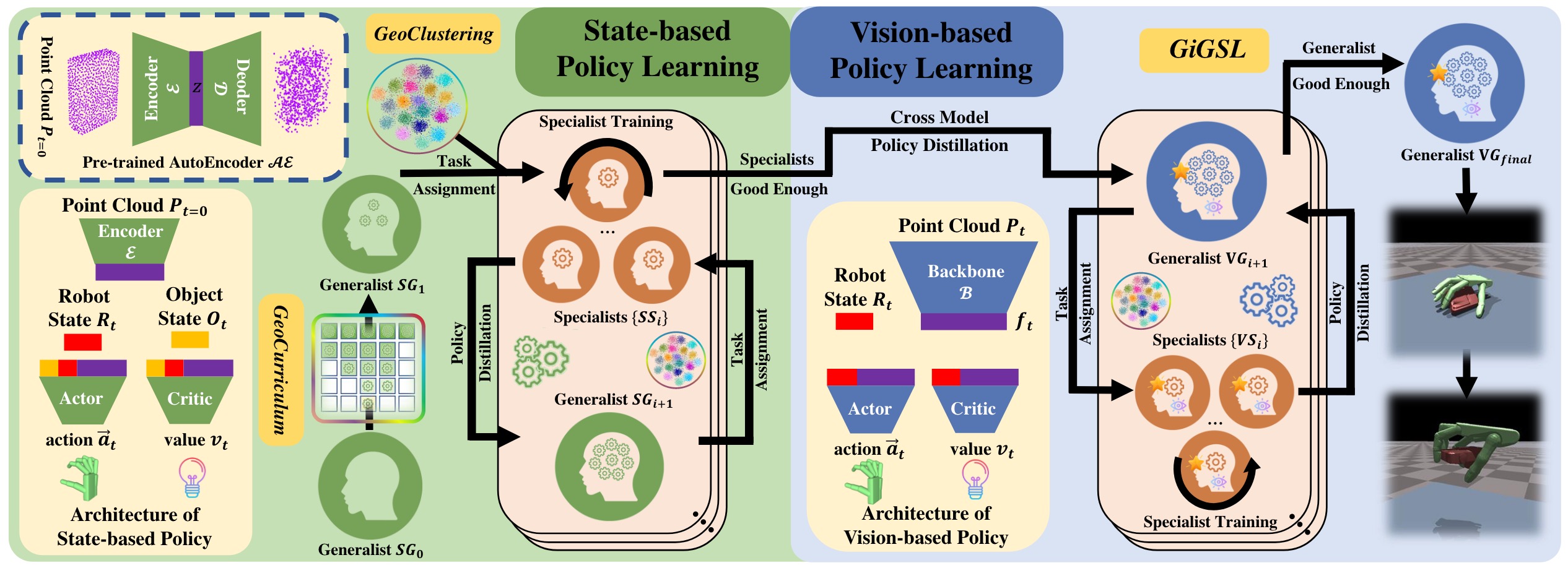
Method Overview. We propose to first adopt a state-based policy learning stage
followed by a vision-based policy learning stage. The state-based policy takes input
robot state Rt, object state St, and the geometric feature z of the scene point cloud
of the first frame. We leverage a geometry-aware task curriculum (GeoCurriculum) to
learn the first state-based generalist policy. After that, this generalist policy is
further improved via iteratively performing specialist fine-tuning and distilling back
to the generalist in our proposed geometry-aware iterative generalist-specialist
learning (GiGSL), where the task assignment to which specialist is decided by our
geometry-aware clustering (GeoClustering). For vision-based policy learning,
we first distill the final state-based specialists to an initial vision-based
generalist and then do GiGSL for the vision generalist, until we obtain the final
vision-based generalist with the highest performance.