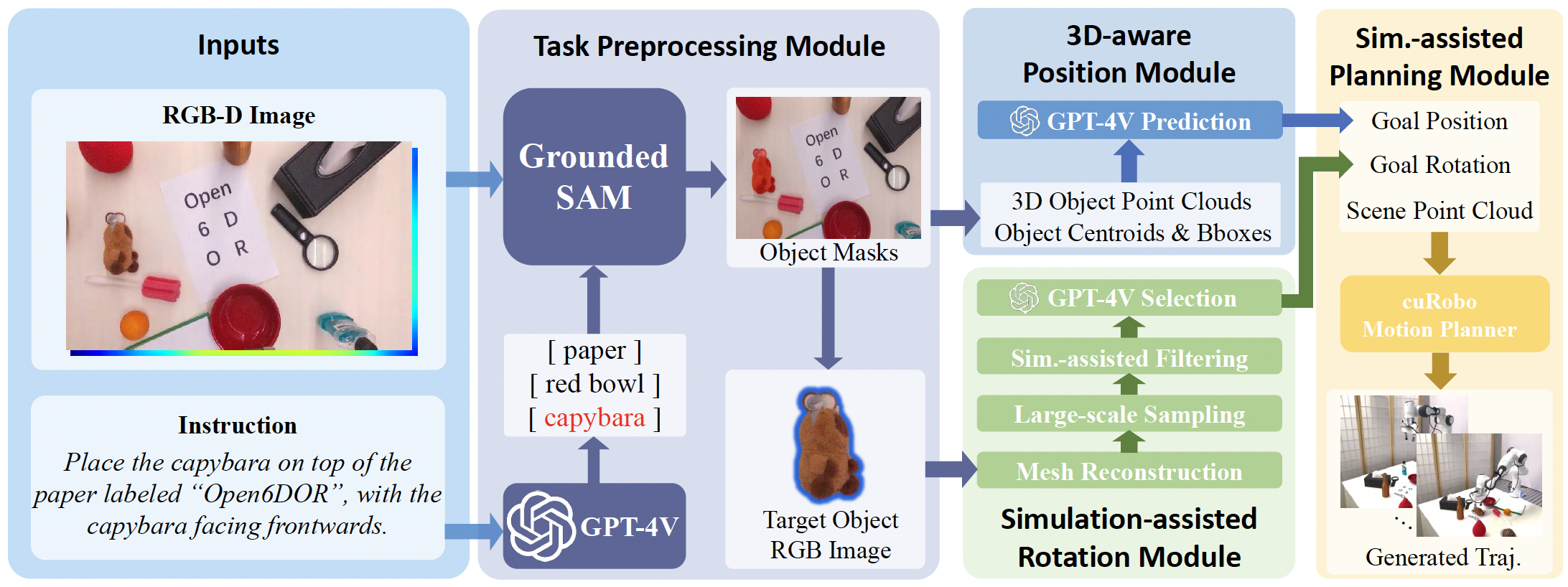
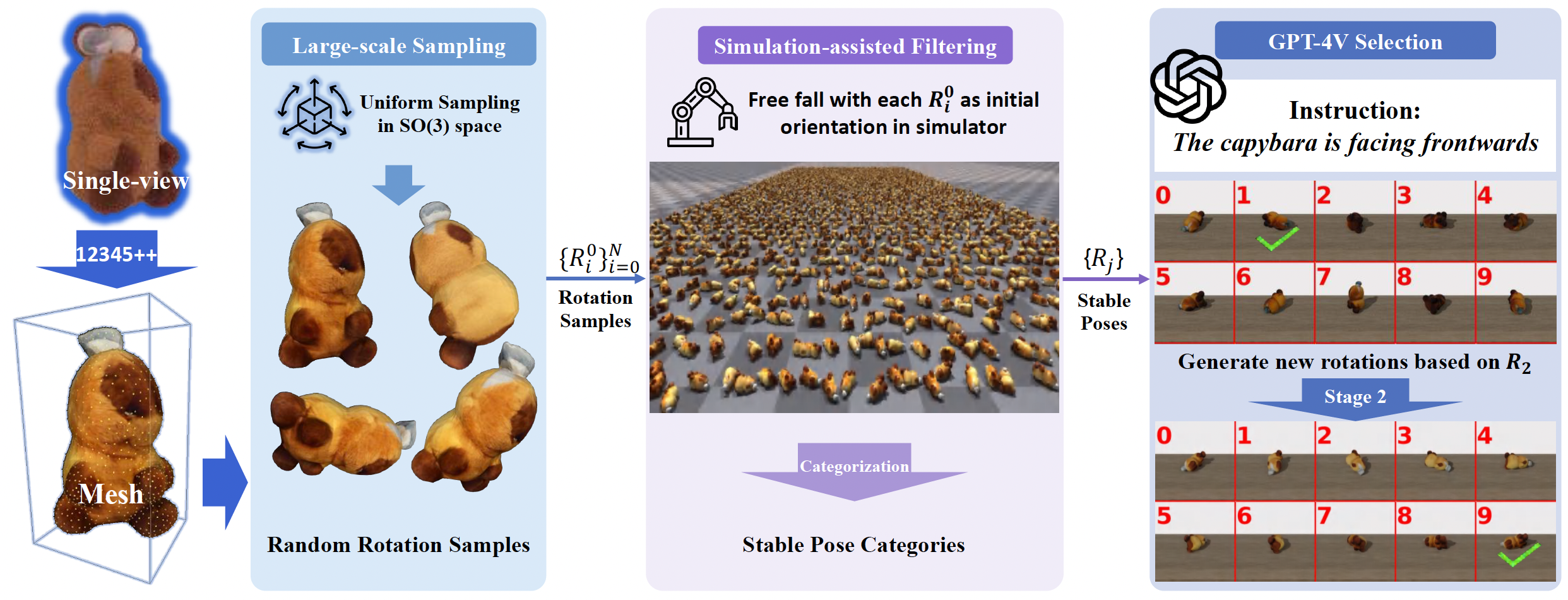
Open6DOR Benchmark and Real-world Experiments. We introduce a challenging and comprehensive benchmark for open-instruction 6-DoF object rearrangement tasks, termed Open6DOR. Following this, we propose a zero-shot and robust method, Open6DORGPT, which proves effective in demanding simulation environments and real-world scenarios.