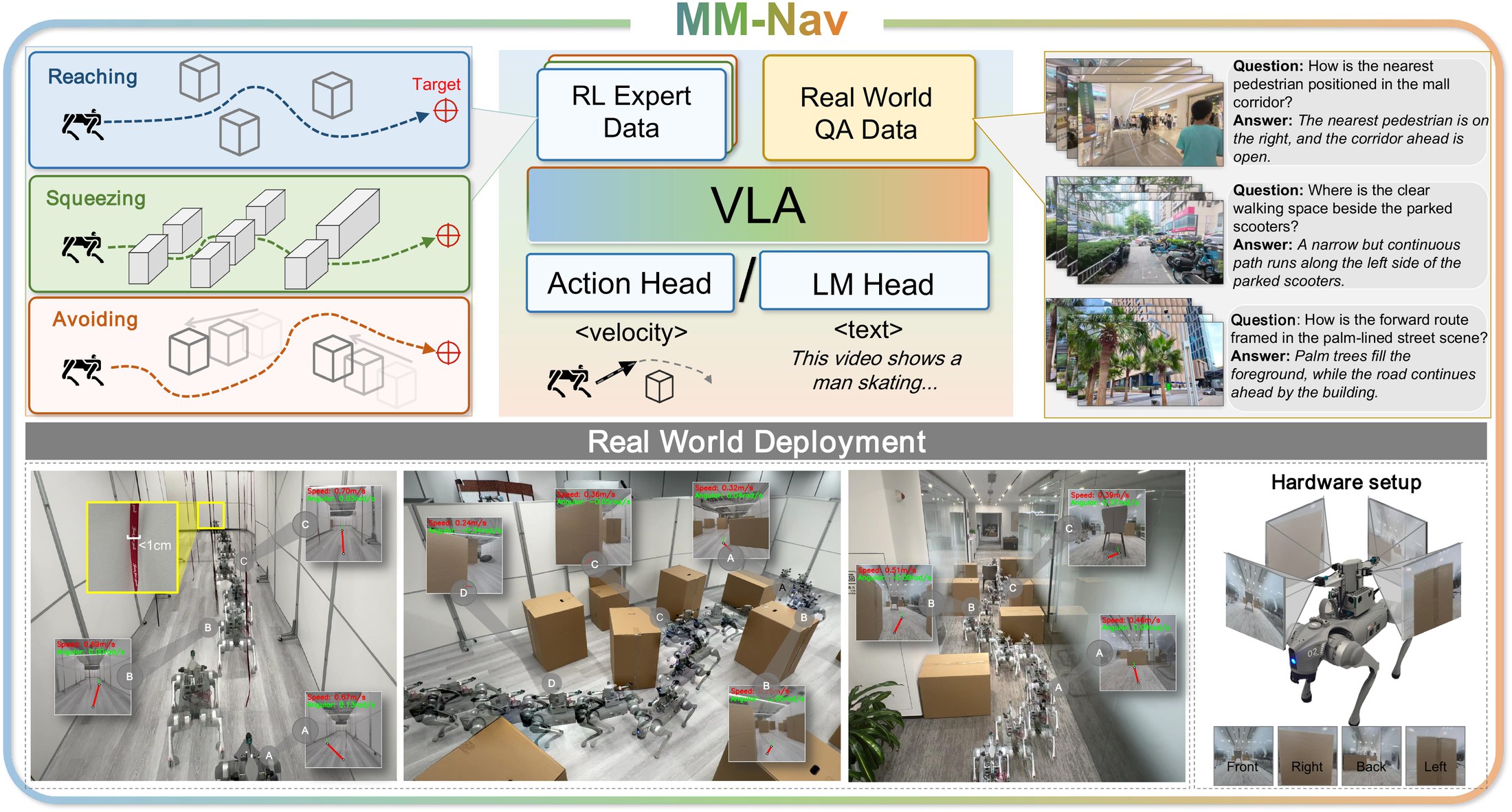
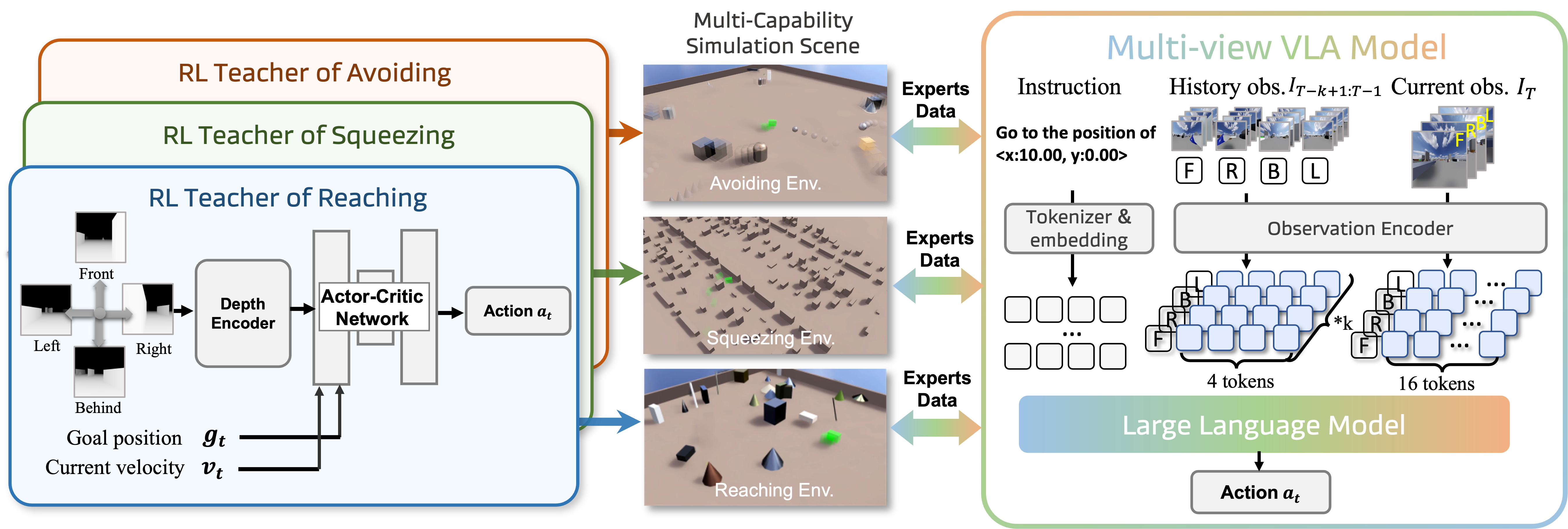
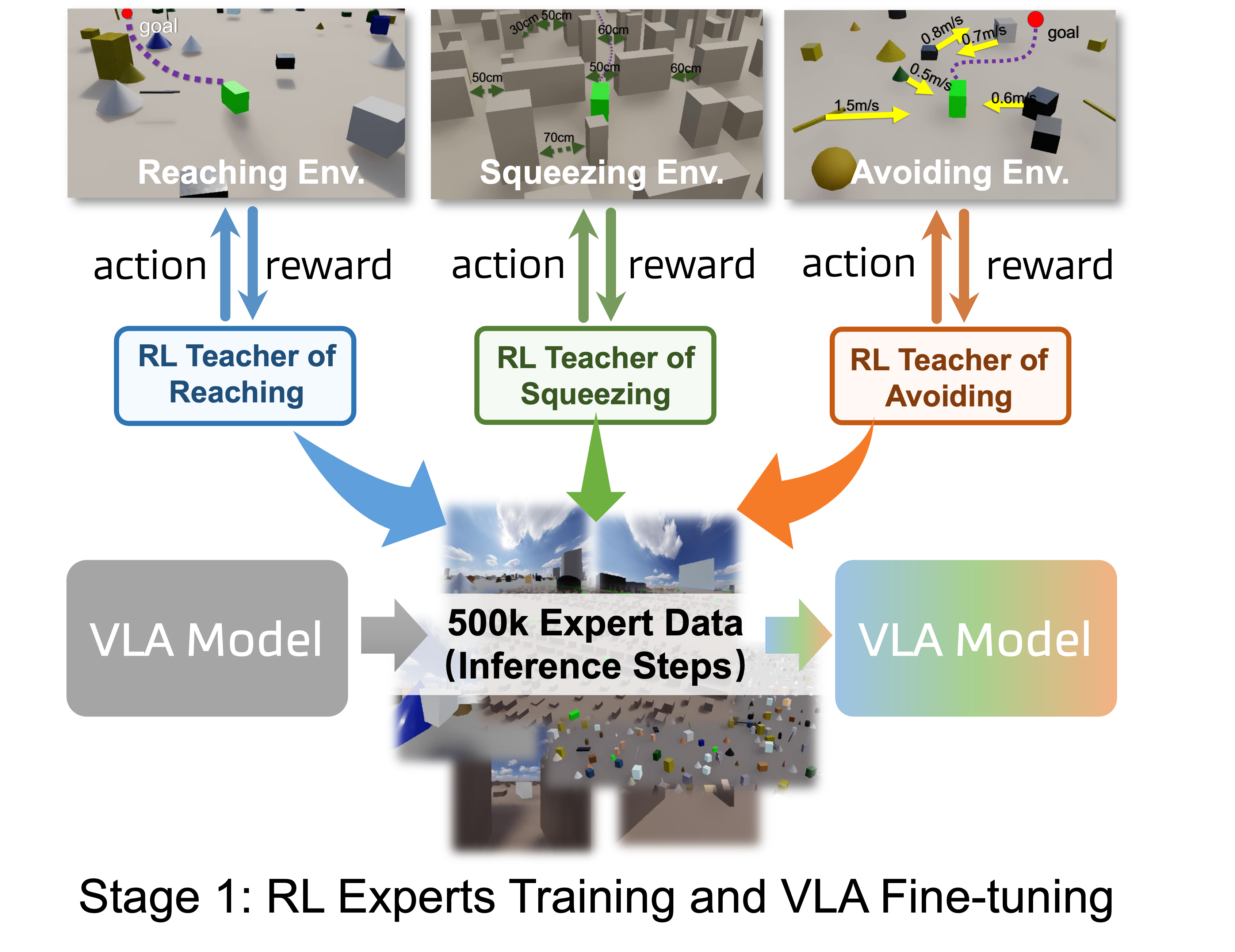
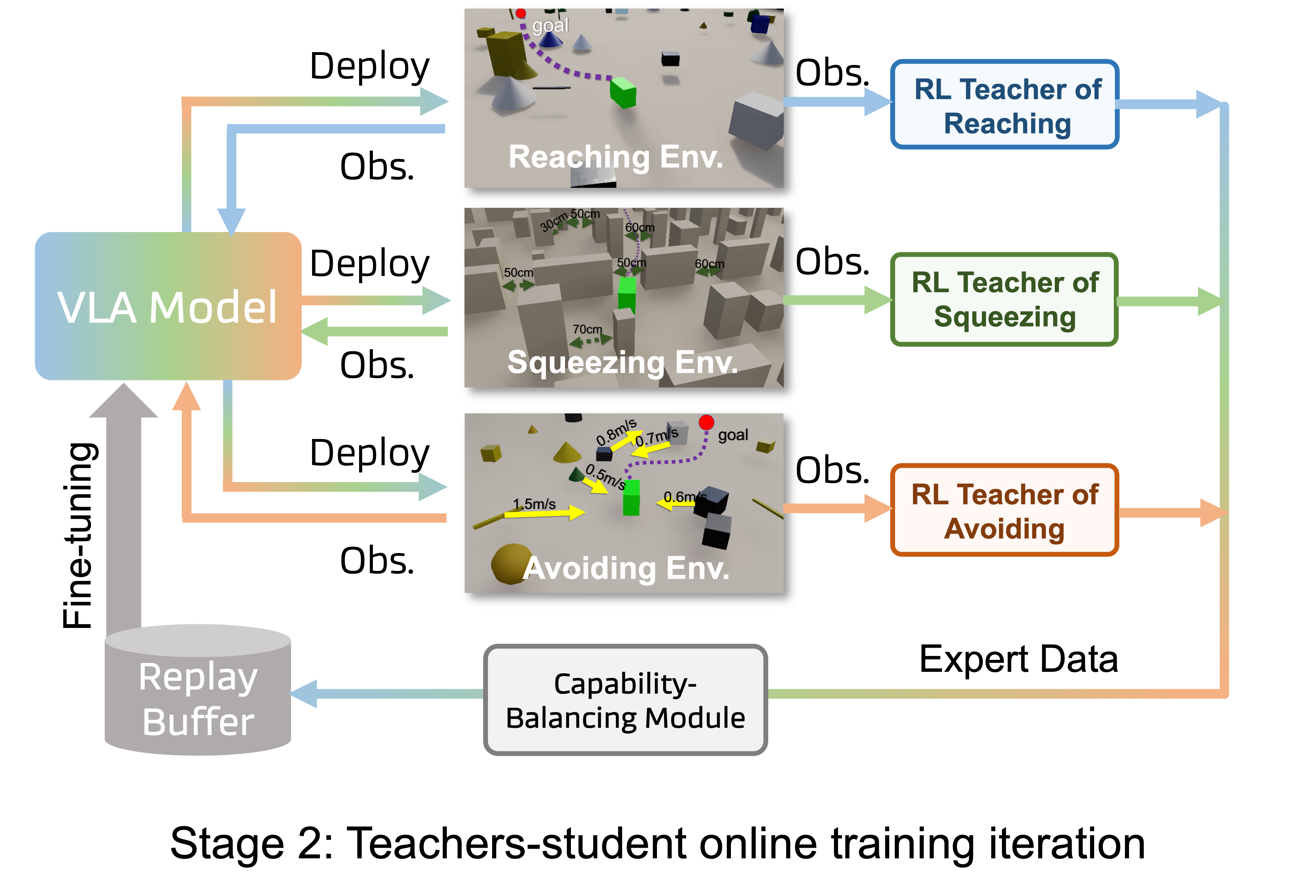
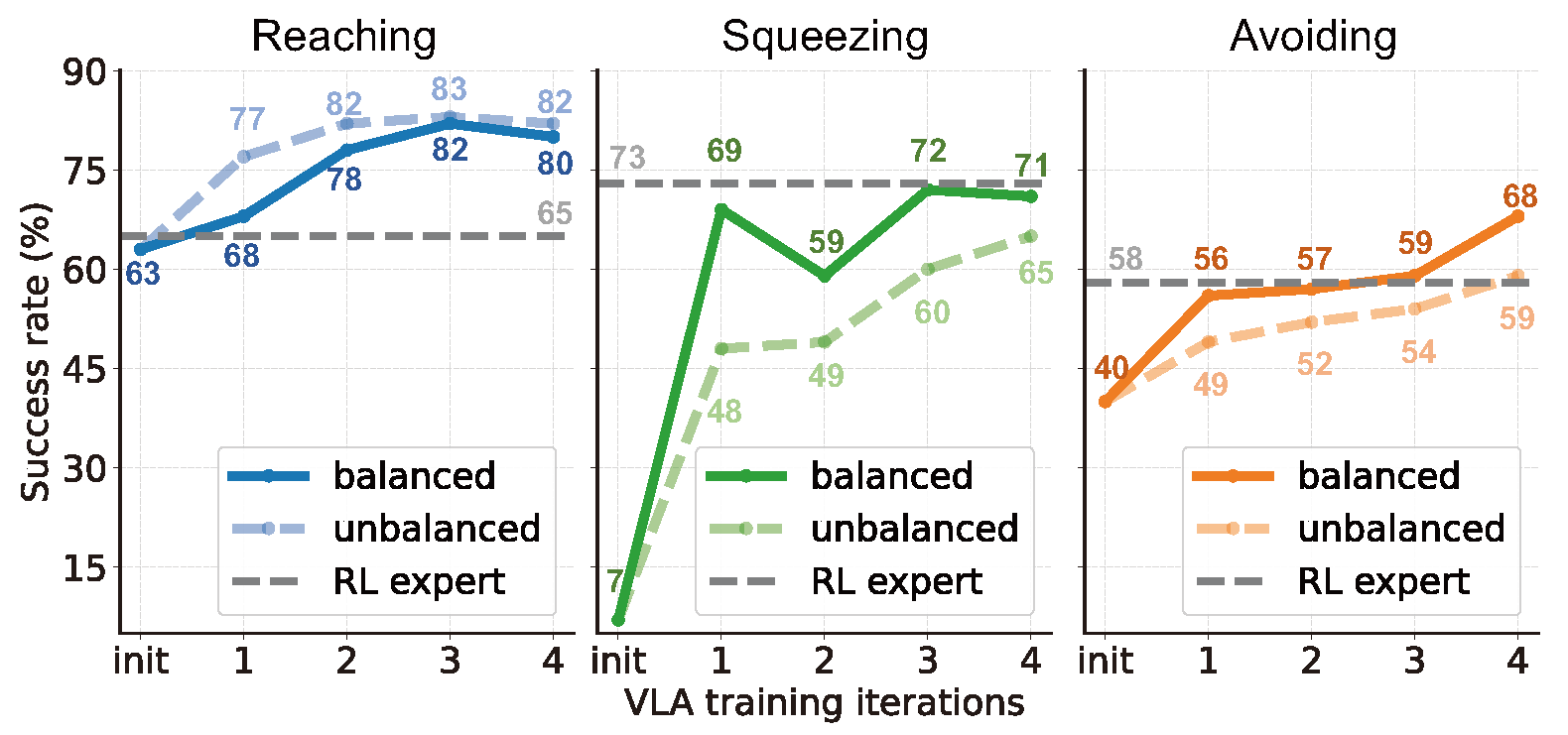
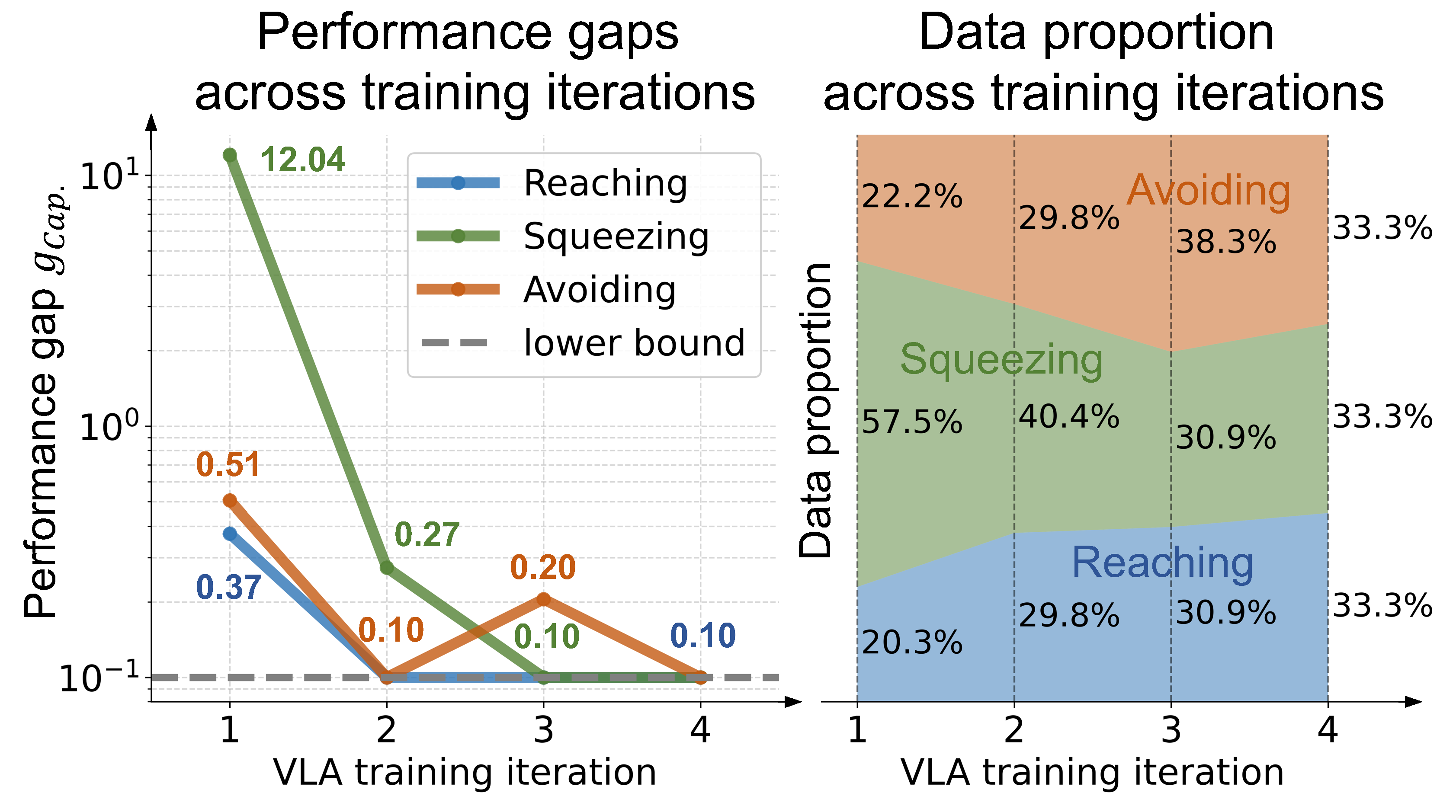
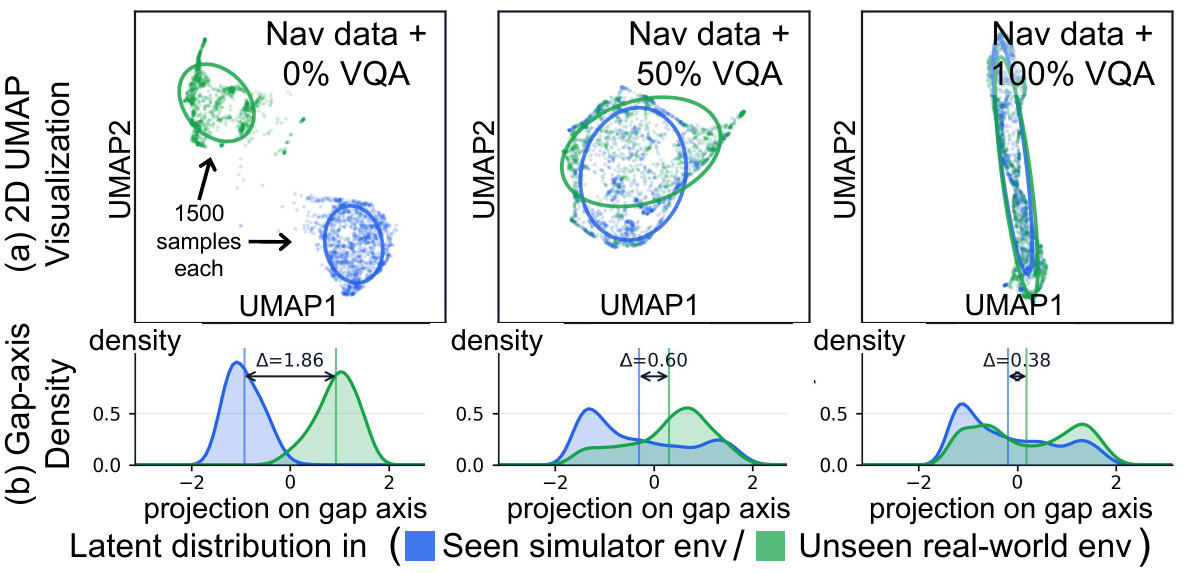
We introduce MM-Nav, a 7B multi-view VLA model for robust visual navigation with 360° observation and 7 Hz inference. MM-Nav learns from 1.5M expert demonstrations collected from three privileged RL teachers specialized in reaching, squeezing, and avoiding, and co-trains on large-scale real-world VQA data to reduce the sim-to-real gap. On the InternVLA-N1 System-1 point-goal navigation benchmark, MM-Nav achieves an 88.1% success rate.