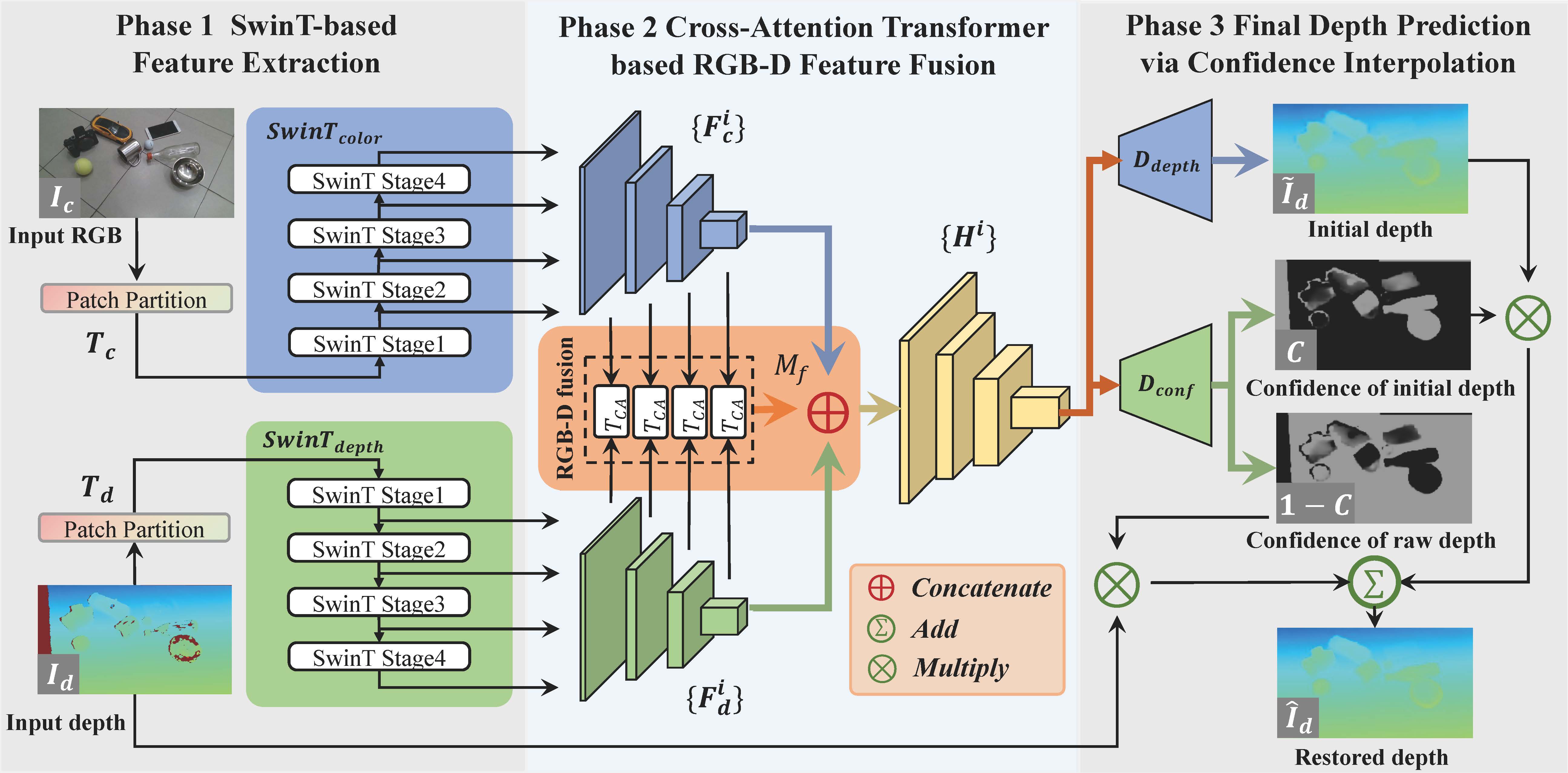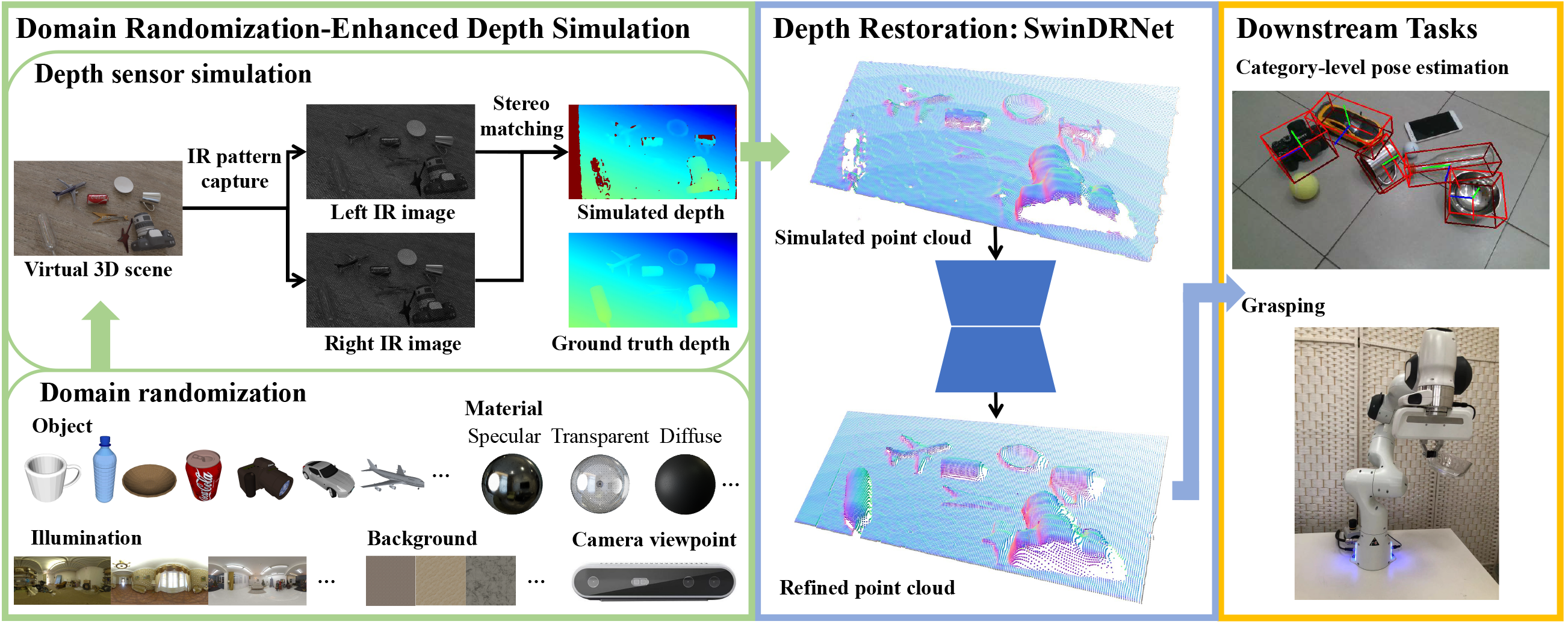
Figure 1. Framework overview. From the left to right: we leverage domain randomization-enhanced depth simulation to generate paired data, on which we can train our depth restoration network SwinDRNet, and the restored depths will be fed to downstream tasks and improves estimating category-level pose and grasping for specular and transparent objects.