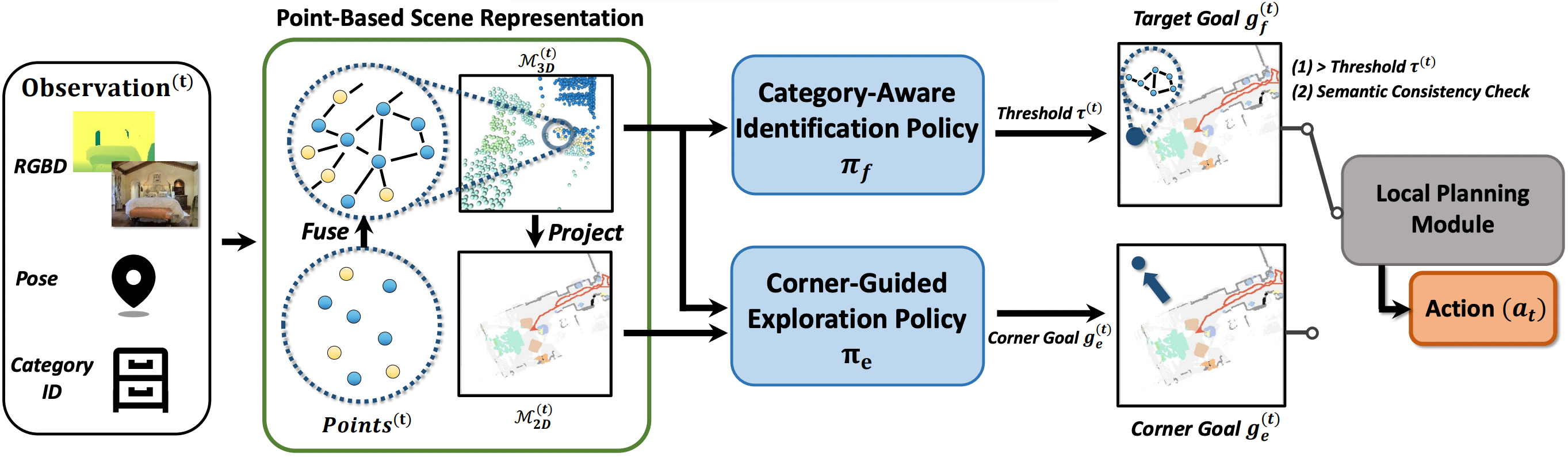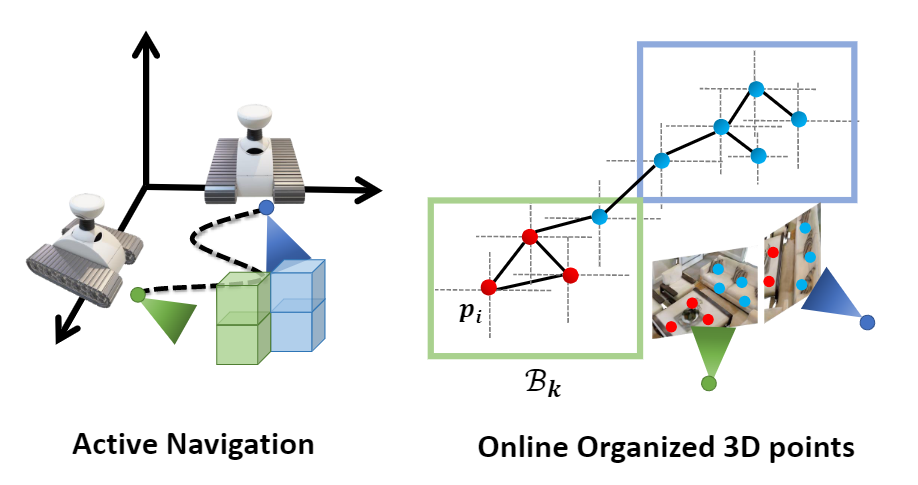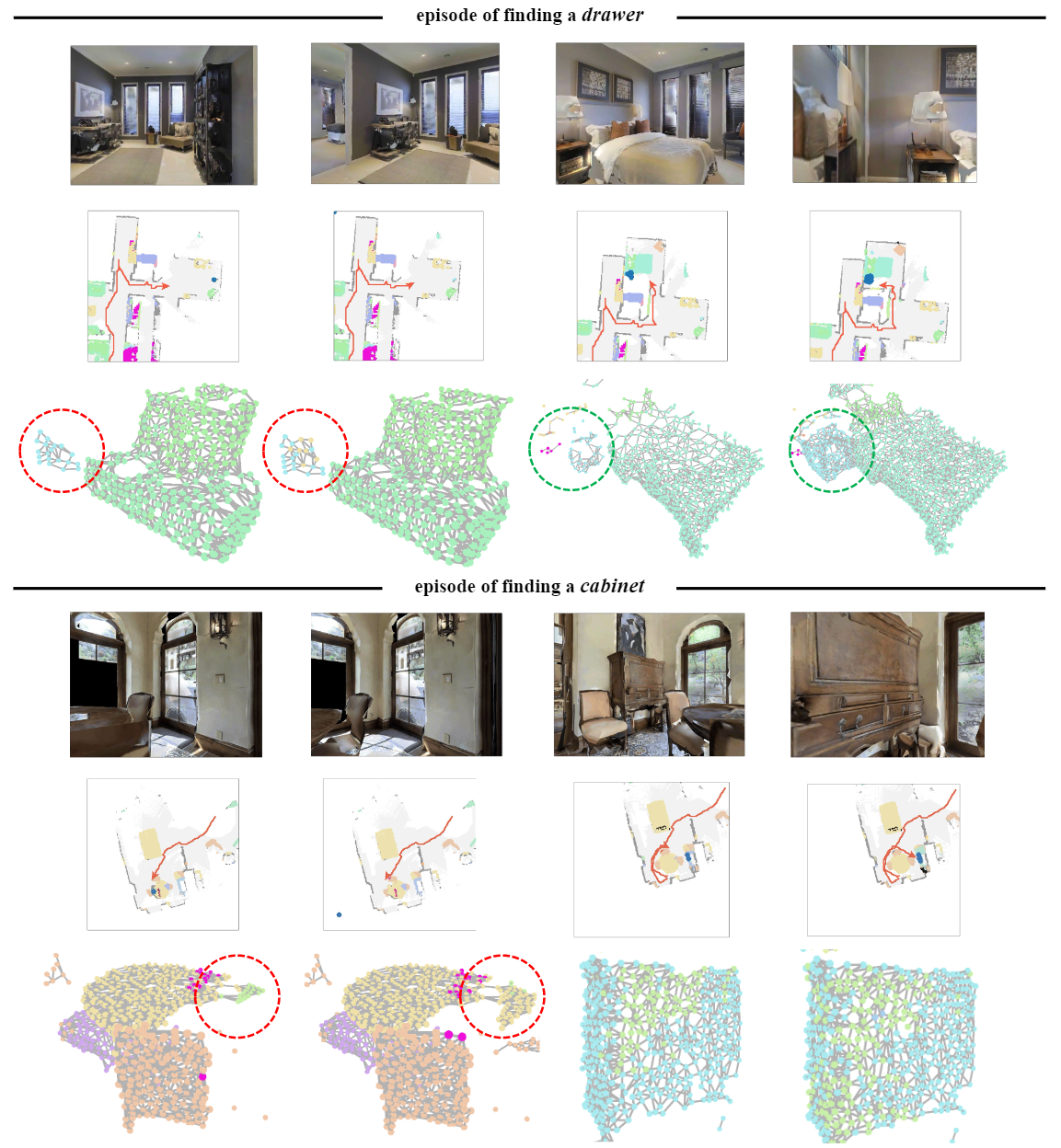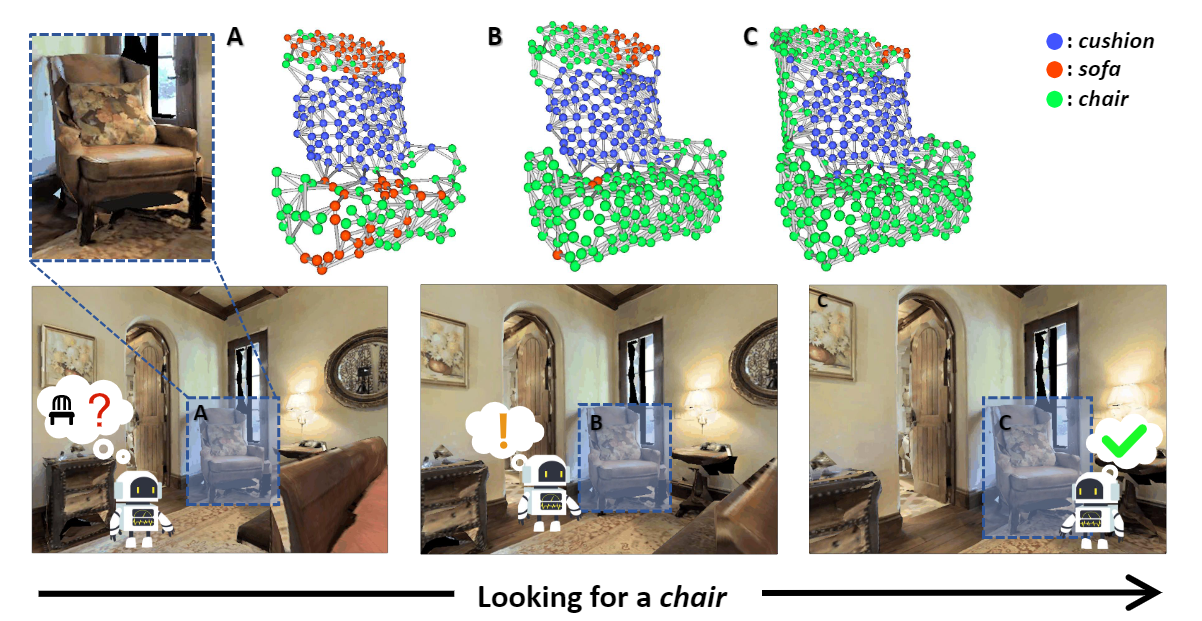
Teaser. We present a 3D-aware ObjectNav framework along with simultaneous exploration and identification policies: A$\rightarrow$B , the agent was guided by an exploration policy to look for its target; B$\rightarrow$ C , the agent consistently identified a target object and finally called STOP.